


GAやGTMのセッティングをしているとちょろちょろ出てくる「正規表現」。使いこなせると色々時短できたり、普通に画面を操作するだけでは実現できないことが出来たりするスグレモノですが、一方、設定がうまくできずにドツボにハマりやすい曲者でもあります。
この記事ではマーケターが正規表現を使うことを想定して、僕がドツボにハマったことがある点を中心に注意したいポイントをまとめてみます。
正規表現が使える場所
まず、正規表現がどこで活用できるのかをまとめます。
Google アナリティクス(GA4)
主に「探索」のフィルタで使います。
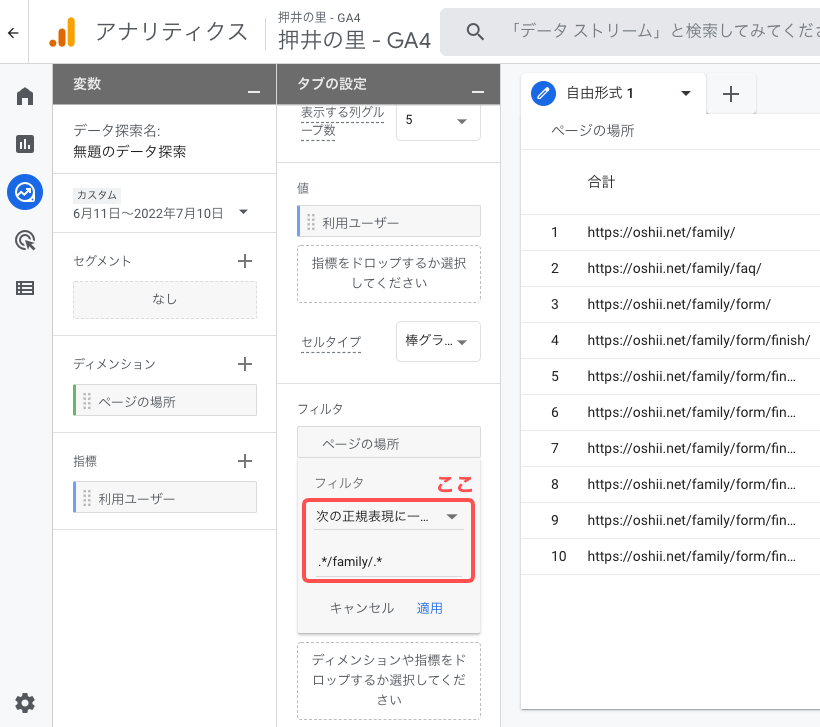
ユニバーサルアナリティクスのほうではどのレポート画面でもだいたい使えましたが、GA4では通常レポートでは使用できず、正規表現を使用したい場合は「探索」のフィルタで使うのが基本になりました。後述しますがここの正規表現はちょっとクセがあって、UAと同じ感覚で使うと結果がすぐ0件とかになり、全然使えません。
上記以外では、GA4だと使う場所はあまり無いと思います。UAだと、いわゆる社内IP除外のときに正規表現が使えたんですが、GA4では内部トラフィックの定義に正規表現が使えなくなったので、出番が減りました。
あと「カスタムイベント作成」機能では現状、正規表現一致が使えないんですが、要望が多いみたいなのでこれはゆくゆく使えるようになるかも知れません。
Google タグマネージャー
用途は主に3つあります。
トリガーの一致条件
一番多い使い方。Page Path がこの正規表現のときに、タグ発火する、みたいな感じで使用します。正規表現に一致する、しないのどちらかを選べます。
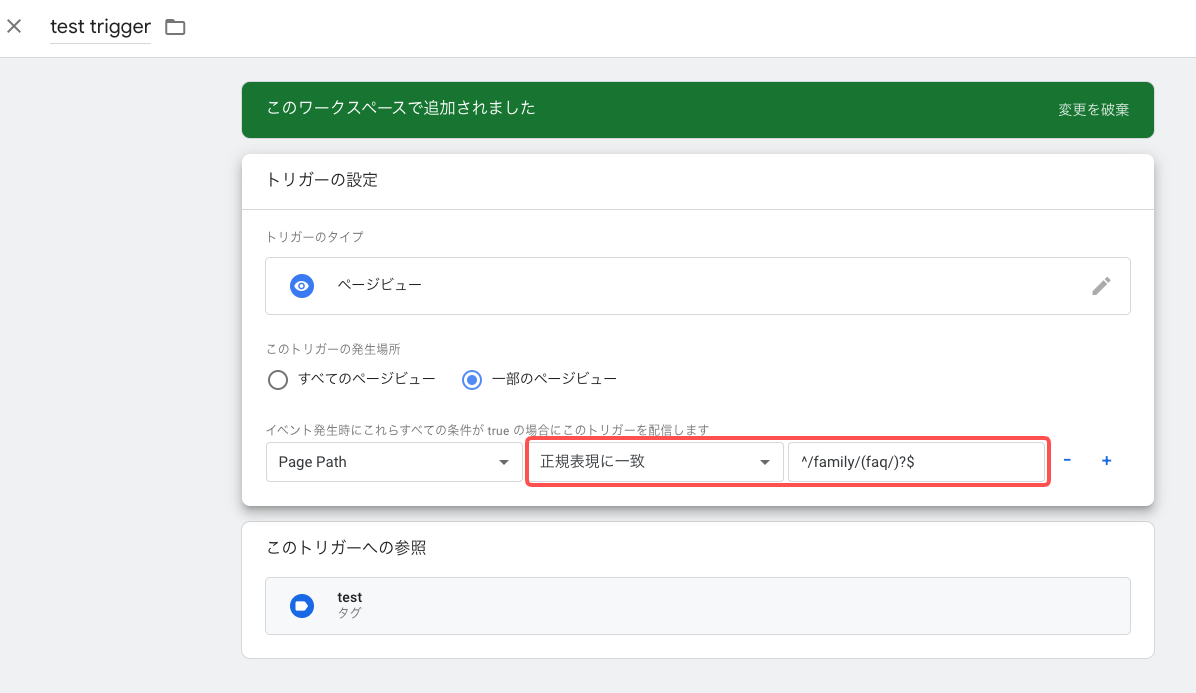
トリガーは、正規表現を使わない場合は条件を or で設定することができません。ご覧のとおり「すべての条件が true の場合にこのトリガーを配信」しかできない仕様になっています。
「ページA または ページBで発火」のような設定を行いたい場合は、トリガーを別々に作成してタグに設定することでも実現できますが、「わざわざ別々にトリガーを作成するのはめんどくさいなあ……」という場合は、正規表現で作ります。
「正規表現の表」変数
ユーザー定義変数の1つで、最初に入力する別の変数を決め、その変数の値が指定する正規表現にマッチした場合に、マッチした箇所を指定した別の値に置き換えるというもの。
僕は「コンテンツグループ」の設定で使っています。
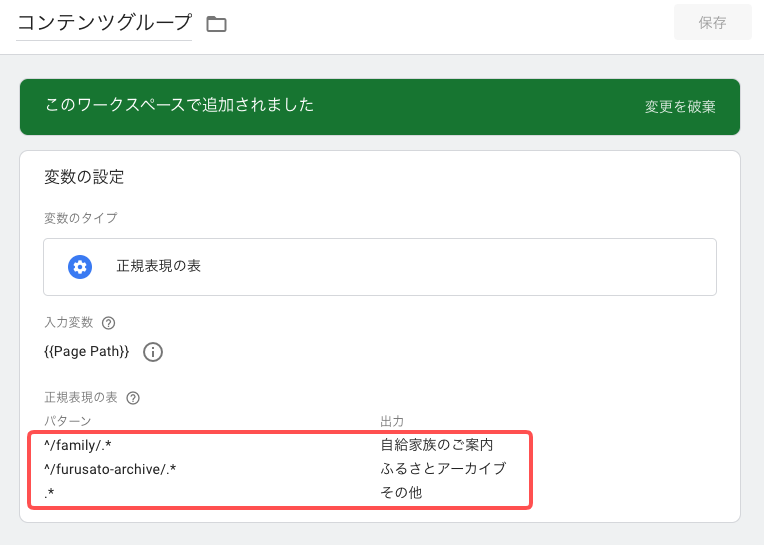
パターン検索は上から順に実行されて、マッチした箇所が出力の項目に置換されます。JavaScript の if…else 文に似てますね。最後は .* で、上でマッチしなかったやつを全部「その他」に放り込みます。
検索はデフォルトでは「完全一致」で行われますが、「Advanced Settings > 完全一致のみ」のチェックを外すと部分一致で置換が行われます。ただこのとき置換されるのは「部分一致でマッチした箇所のみ」なので、気をつけて設定しないと変数の値がおかしな内容になります(そういう挙動を意図しているなら別です)。
正規表現の表は、もともと似た機能として「ルックアップテーブル」という別のユーザー定義変数があったんですが、こちらは一致条件として正規表現一致を使えなかったため、正規表現一致も使えるようにということで出来た変数らしいです。詳しくはアユダンテさんのこちらのブログ記事で解説されています。
「カスタム JavaScript」変数
たとえば、とある画面上から価格の情報を抜き出してGA4イベントタグに仕込みたい。だけど、よく見るとHTMLが
<span class="price">2,200円(税込)</span>みたいになっていて、「円(税込)」の部分は要らないんだけど、DOM要素変数では価格のみを抜き出して取ってくることができない、という場合。
JavaScriptの replace() メソッド や match() メソッド を使えば、値を自由に加工することができるので、上記のようなケースでも「2200」のみを取り出すようなことが可能になります。このときに正規表現を使います。また「カスタムHTMLタグ」の中で JavaScript を書いた場合も同じことができます。
その他ツール
雑にまとめちゃいますが、URLを指定して検索したりするツールではだいたい正規表現での検索機能が備わっているので、そこで使えます。
- Google サーチコンソール(SEO)
- Google オプティマイズ(ABテスト)
- Microsoft Clarity(ヒートマップ)
あと、普通のテキストエディタでも正規表現を使うことがあります。どういう時かというと、大量のデータを、正規表現を使って指定の形式に置き換えたい、みたいなときにごく稀に使います。ほんとに稀です。だいたいは普通の置換とか、矩形選択とかで力技するだけで済むので。
上記以外にも、Excelやスプレッドシートでも使える、BigQueryでも使える、データポータルでもちょっと使える、など挙げればキリがありませんが、とにかくいろいろ使えます。
正規表現を使うときの注意点
このように結構、活用の幅が広くて便利な正規表現ですが、注意したい点がいくつかあります。
否定など、場所によって使えない記述がある
例えば上記のうち、JavaScript変数以外はいわゆる「否定」の表現が使えません。具体的には下記のような書き方です。
^(?!abcdef)(abc|ghi).*$このように「abc と ghi で開始するやつはマッチさせたいけど、abcdef はマッチさせたくない」みたいなケース。URLを対象とした検索だとそこそこ出てくるんですが、GA4で入力するとエラーが発生します。
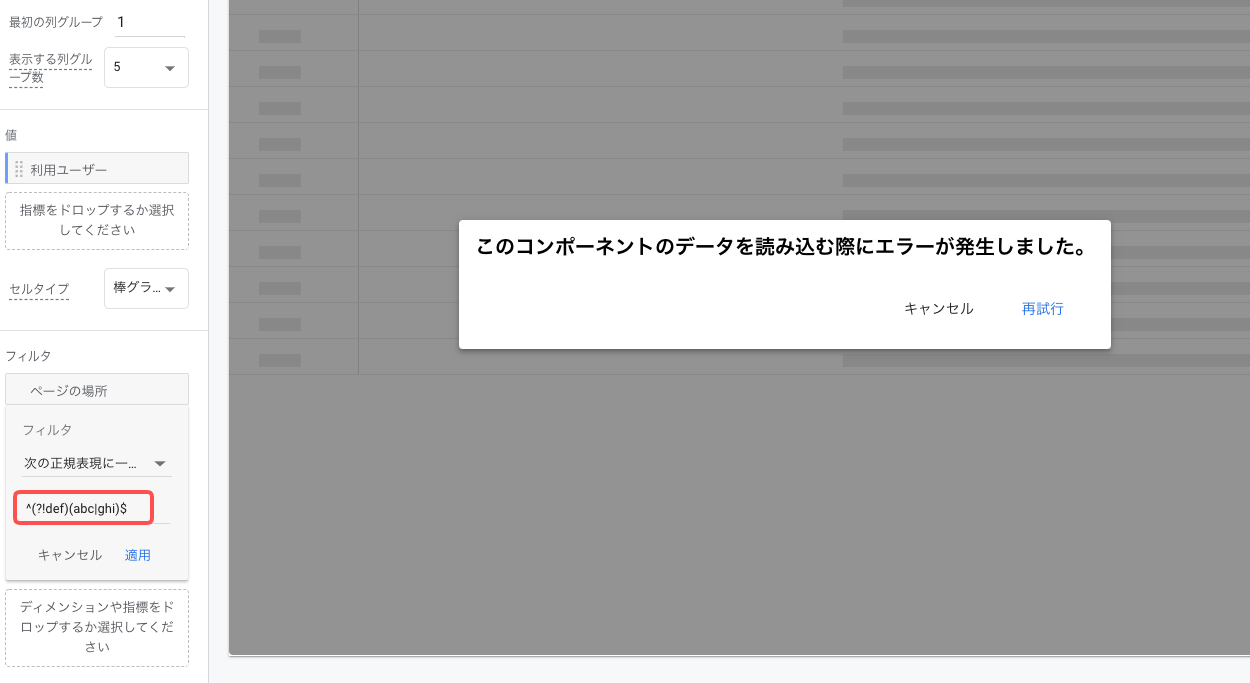
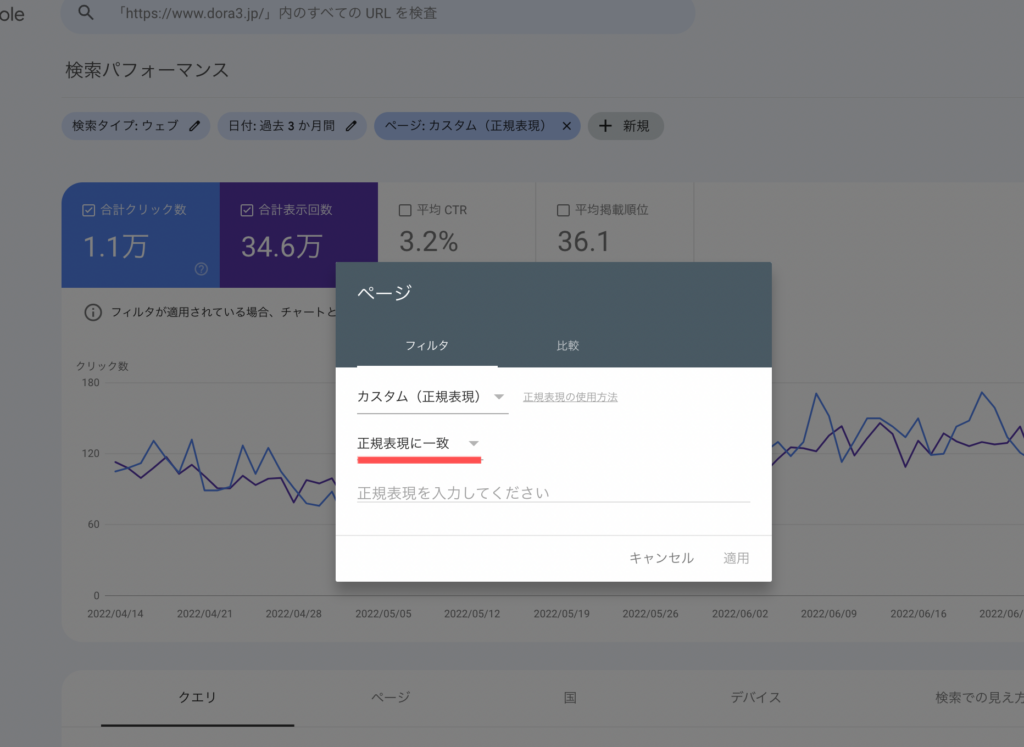
この場合どうすれば良いかというと、「否定」の部分を「正規表現に一致」ではなく「正規表現に一致しない」で下記のように別のフィルタとして設定します。なのでフィルタが2つになります。気持ち悪いですがこうするしかありません。
ただし、例えばサーチコンソールでは「ページ」の正規表現一致条件を同時に2つ以上設定する機能がないので、これもできません。従って少なくとも画面上で出すのは諦めるしかありません orz
このように、正規表現は環境によって使えるものと使えないものがあるので、知っておきましょう。
なお、GAでどの正規表現が使えるのかというのは「正規表現(regex)について」というヘルプページで簡単に解説してあります。加えて、このページの末尾に「Google RE2 正規表現の構文」というGitHubへのリンクがあって、詳しいことはここで解説されています。英語ですが。RE2というのが、Googleが定める使用可能な正規表現ですよ、ということみたいです。
で、このページをよく見ると、[^xyz] といった「一文字だけの否定」であれば使えるような書き方がしてあります。ただ、これが実務で必要になったことが一度もないのと、あと実際にGA4で使ってみたんですがどうもうまく動いていないっぽく、結論、否定は使えないで良いと思います。
GA4の正規表現検索は「完全一致したもの」を返す
上に挙げたツールの管理画面で正規表現検索を行うと、GA4以外は「部分一致したもの」が返ってきます。しかし、GA4では「完全一致したもの」が返ってきます。
たとえば hogehoge.com というサイト内でURLに「blog」と入っているページのみを抽出して結果を知りたい、みたいなケースを想定します。もちろん「blog」は正規表現で検索する必要なんてないんですが、ここでは「blog」を正規表現検索すると仮定します。すると検索したときに内部では下記のような形になっています。
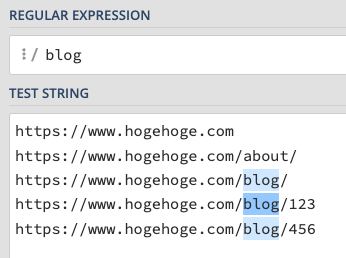
これは正規表現チェックツールの Regex101 でテストしたものですが、意味としては5つのURLのうち下3つが部分一致していることを表しています。このときツールの管理画面でどうなるかというと、UAでは下3件が部分一致しているため、これらが結果として返ってきます。ところが、GA4では完全一致しているURLが1つもないため、結果は0件になってしまいます。
ではUAでもGA4でも同じ結果を得るにはどうすればよいかというと、下3件を完全一致させればよいわけなので、
.*blog.*このように書きます。すると下記のようになってUAでもGA4でも下3件が返ってくることになります。
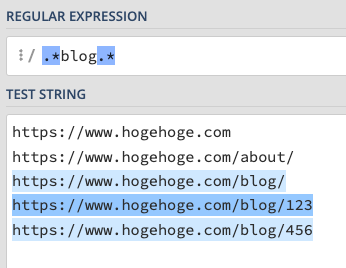
この仕様はつい先日「正規表現(regex)について」のページでも追記されました。なぜこういう仕様になっているのかは謎ですが、これを知らないとGA4で正規表現検索をしたときに実際よりも件数が少ないとか、はい0件ね、みたいな感じで思い込んでしまうことがあるので、気をつけましょう。
正規表現は長くてもあんまり問題ない
サーチコンソールで「記事カテゴリごとの検索評価」を調べたいのだけど、記事のパスが /category/hogehoge/xxxxx のようにキレイにカテゴリ分けされていなくて、 /xxxxx だけ、みたいになっている場合。どうすればカテゴリごとの検索評価を出力できるでしょうか?
このとき「カテゴリごとの記事パス一覧」が分かるのであれば、それを | (パイプ)で全部つないでめちゃくちゃ長い正規表現を作成し、検索するという力技が使えます。
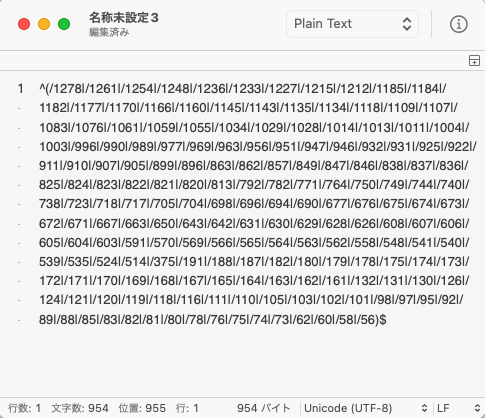
こういう感じで、記事URL一覧からテキストエディタの置換機能を使って長い正規表現を作成し、サーチコンソールの正規表現一致条件としてブチ込みます。954文字ありますが、余裕で動きます。重くなったりしないの?とか思うかもですが全然そんなことありません、サックサクです。
ちなみにこれ、どれくらいの文字数まで耐えられるのかと思ってさっき試してみたんですが、4097文字目で「入力したテキストが長すぎます」というエラーが出たので、4096文字まではどうやらいけそうです。
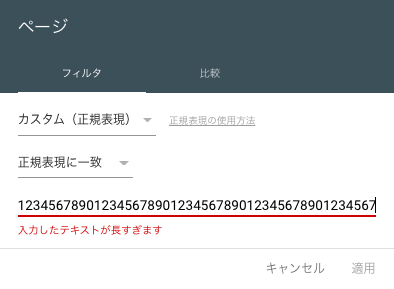
なお、GA4の正規表現フィルタは文字数上限がけっこう厳しく、256文字となっています。少ない……こんな力技に頼らずに dataLayer とかで頑張れってことかも知れませんが、それにしてももうちょっと頑張ってほしいよなあ。
/ のエスケープはGA等では基本的に不要
正規表現の例文とかをググると、出てくるもののなかに / (スラッシュ)をエスケープして \/ という書き方をしているものと、エスケープしていないものが混在しています。
^https://hogehoge\.com/about/$
^https:\/\/hogehoge\.com\/about\/$最初これ、どっちが正しいのか分からなくて、エスケープしたりしなかったり、両方打って確かめたりしていたんですが、結論としてはGAでは / のエスケープは不要です。
そもそもエスケープというのは正規表現のいわゆるメタ文字を「普通の文字」として扱ってもらうために行う処理ですが、/ はメタ文字ではありません。じゃあ何かというと、JavaScript を書くときに「ここからここが正規表現ですよ」ということを表すための区切り文字としてよく使われる文字になります(デリミタと言います)。
// スラッシュをエスケープした場合
'https://www.hogehoge.com'.replace(/https:\/\//, '');
// → 'www.hogehoge.com'
// スラッシュをエスケープしなかった場合
'https://www.hogehoge.com'.replace(/https:///, '');
// → Uncaught SyntaxError: missing ) after argument list左側の緑色は検索対象となるただの文字列で、右側の replace() メソッド内にある赤文字が正規表現です。
JSのコード中で正規表現を使用する場合、区切り文字で / を使っているのにその途中でも / を使ってしまったら、どこが正規表現の区切りなのかJSが正しく判別できなくなって上記のようにエラーが起こるので、途中の / は区切り文字じゃありませんよということを表すためにエスケープする必要があるんですね。
一方、GAで正規表現を使うときは検索条件の入力枠があるだけで区切り文字なんてありませんから、エスケープは要らないというわけです。
あってもなくても結果は同じなので、JS等での使い回しを想定して最初から必ずエスケープするルールにしちゃう、とかでもありかもしれません。ただ、/ はURLで頻繁に出てくる記号で、毎回全部エスケープするのはまあまあ大変なので、僕はしなくても良いと思います。
記述が正しいかどうかの確認は慎重に
正規表現は、正しい記述を一発で書けるということはあまりなく、どんなに慣れていても最初に書いたものはだいたい間違っています。なので、自分はいつも間違えるという前提に立ち、どこが間違っているのかを確かめられる環境を用意しておくのがとても大事です。
このときに使えるのが前の章でしれっとキャプチャで出した「正規表現チェックツール」というもので、
- 自分で書いた正規表現
- 正規表現の検索対象となるサンプルデータ
これらを用意すれば、正規表現が正しく書けているかどうかをチェックすることができます。ツールはWebサービスとして提供されており、「正規表現チェックツール」などで検索すればたくさんヒットしますが、僕は「Regex101」というのを使っています。世界中で使われているメジャーなツールらしいです。
サンプルデータは、ヒットしてほしいやつと、してほしくないやつを5個ずつなど、良い感じで混ぜて作りましょう。
また、正規表現チェックツールでのチェックが終わった後、万全を期したい場合には、さらにGAの実データで実際に検索してみると尚良しです。この段階でヒット漏れや、除外漏れが発見されるケースも多々あります。
正規表現の基礎は一通り押さえよう
上に書いているツールを使ったり、ググって正規表現の例文をコピペしたりすれば、正規表現をそれなりに活用することは可能です。
しかし、基礎を押さえず、書いている内容の意味を正確に理解せずになんとなく使っているといつかデカイ事故を起こしかねません(オプティマイズで変なページに配信しちゃうとか)。あと、そのほうがうまく行かなくなったときに修正がすぐ終わって楽です。面倒だとは思いますがやはり一度さらっと勉強しておくことをおすすめします。
僕はUdemyの「正規表現講座 改訂版 – 初歩から応用まで」という有料の動画講座で学習しました。下記は無料版で見られる箇所のキャプチャですが、こうやって Regex101 を使って学習を進める立て付けになっています。
無料で勉強したいという場合は、ドットインストールの正規表現講座もおすすめです。
動画視聴のしかたですが、まずは自分で書くことはせず、全部見るだけにしましょう。なぜかというと、Webマーケ仕事で本当に必要な正規表現というのはかなり少なく、最初から全部きちんと理解しようとすると時間が掛かりすぎてしまうからです。一旦、見るだけ見ましょう。見るだけなら2時間で必ず終わります。
加えて、よく使う項目を自分でも打ってみたりして体に覚えさせていくんですが、そんなこと言われてもどれがどうとか分からないと思うので、下記にたぶん仕事でよく使うっぽい項目を洗い出してみたので参考にしてください。
- 基本
└ 文字列検索、メタ文字、ワイルドカード、角括弧、ハイフン、キャレット、ドルマーク、バックスラッシュ - 数量詞
└ 基礎、回数の指定 - グループ化
└ 丸括弧とパイプ、選択肢のネスト
これ以外の、冒頭で挙げた「否定」とか、「修飾子」とかは、難しいくせに業務で全くと言っていいほど使いませんので、さらっと流し見する程度にとどめましょう。Webマーケ仕事で使う場合は検索対象のほとんどがURLとかページパスなので、それ以外のもの、例えば「メールアドレスのバリデーション」みたいなものも勉強は後回しで良いと思います。
一度書いた正規表現は保管しておこう
先述のとおり正規表現というのは使える場所がいろいろあるので、同じ正規表現を何度も使うようなことが結構あります。
例えば、検索結果ページのパフォーマンスをGAで見て、ふむふむなるほど、じゃあ今度は Clarity で同じページのヒートマップを見てみよう。となったときに、さっき使った検索結果ページの正規表現をまた使うことになります。こういう場合にいちいち毎回正規表現を書いていたのでは非効率ですし、記述を間違えるリスクも大です。
なので、スプレッドシート等でよく使う正規表現をまとめておきましょう。
なお、このときに「なぜこういう正規表現を書いたのか」も併せてメモしておくと、非常に良いです。正規表現は書いたそのときは当然意味がわかるんですが、時間がたってから見るとマジでなんのことだかさっぱり分からなくなっていることがよくあります。そういう事態を回避するために、メモを残しておくと良いです。
よく使う正規表現を辞書登録しておく、というのもおすすめです。僕は下記を「パラメータ」で辞書登録しています。
^(\?.*)?$これは、該当するURLの後ろに ? でパラメータが付いているものもヒットさせたい場合に使う正規表現です。トップページとか、広告用LPのURLを検索したいときによく使います。このままだと何もヒットしないので、^ の後ろにURLやパスを追記して使います。
まとめ
正規表現って見た目が難しい風なので、初学者はちょっと嫌だなあと思うと思うんですが、一回理解しちゃうとなんのことはないモノで、かつ使ってて案外楽しかったりするので、けっこうコスパ良いスキルだよなあと個人的には思っています。
最悪、 | (パイプ)でつなげて or を作るのを覚えてるだけでもけっこう違うんじゃないかと思うので、初学者はまずそこから始めると良いと思います。
